
Gene Nomenclature
In accessing pseudomolecule data from the Rice Genome Annotation Project web site, terms used internally by the Rice Genome Annotation Project such as TU and gene model can be found. The purpose of this page is to explain the nomenclature used by the project and relate it to nomenclature commonly used by biologists.
Transcription Unit (TU):
A transcription unit is equivalent to a gene or locus on the pseudomolecule. Transcription units are stored in the database using a precise naming scheme (feat_name) : x.tyyyyy , where the x refers to the BAC or pseudomolecule assembly id and yyyyy is the distinct identifier of the transcription unit.
Locus Identifier:
For the end user, a complication introduced by the above naming scheme is that the feat_names of the transcription units can change between releases. To circumvent this, locus identifiers for the genes have been implemented in this release of the pseudomolecules. A similar convention as that used for the Arabidopsis genome has been employed, with minor modification for the larger size of the rice genome. Each nuclear gene is labeled LOC_OsXXg##### with LOC_Os referring to Oryza sativa locus, XX referring to chromosome 01-12, g referring to gene, and a 5-digit number referring to the gene order on the chromosome. A convention of LOC_Osp#g##### is used for plastidic genes, while LOC_Osm#g##### for mitochondrial genes. The genes (loci) are numbered sequentially along the chromosome or organellar genome in increments of 10 which will allow for insertion of future loci. Sufficient spacing in the numbering system for physical gaps has been provided in the sequence to allow for insertion of new genes in the event the physical gap is filled. To facilitate integration of the new locus identifiers with genes in our two previous releases, we have developed a Version Converter file to allow users to readily find new locus identifiers for previous genes and models which had been identified solely with feat_names.
Gene Models:
A gene model represents the mRNA transcript of a transcription unit and therefore contains information about features of the transcript such as exon-intron boundaries, splice sites, UTRs, etc. Due to the alternative splicing of mRNA transcripts, more than one gene model can derive from a transcription unit. Gene models have unique feat_names in the database and are linked to the parent transcriptional unit. The feat_names take the form of x.myyyyy , where the x refers to the BAC or pseudomolecule assembly id and yyyyy is the distinct identifier of the gene model.
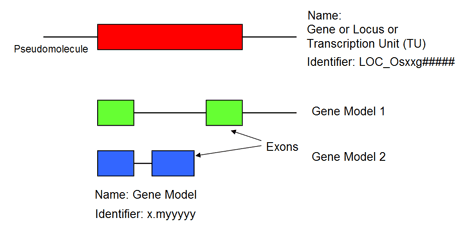
Illustration of the nomenclature used by the Rice Genome Annotation Project

|
|
|
This work is supported by grants (DBI-0321538/DBI-0834043) from the National Science Foundation and funds from the Georgia Research Alliance, Georgia Seed Development, and University of Georgia.